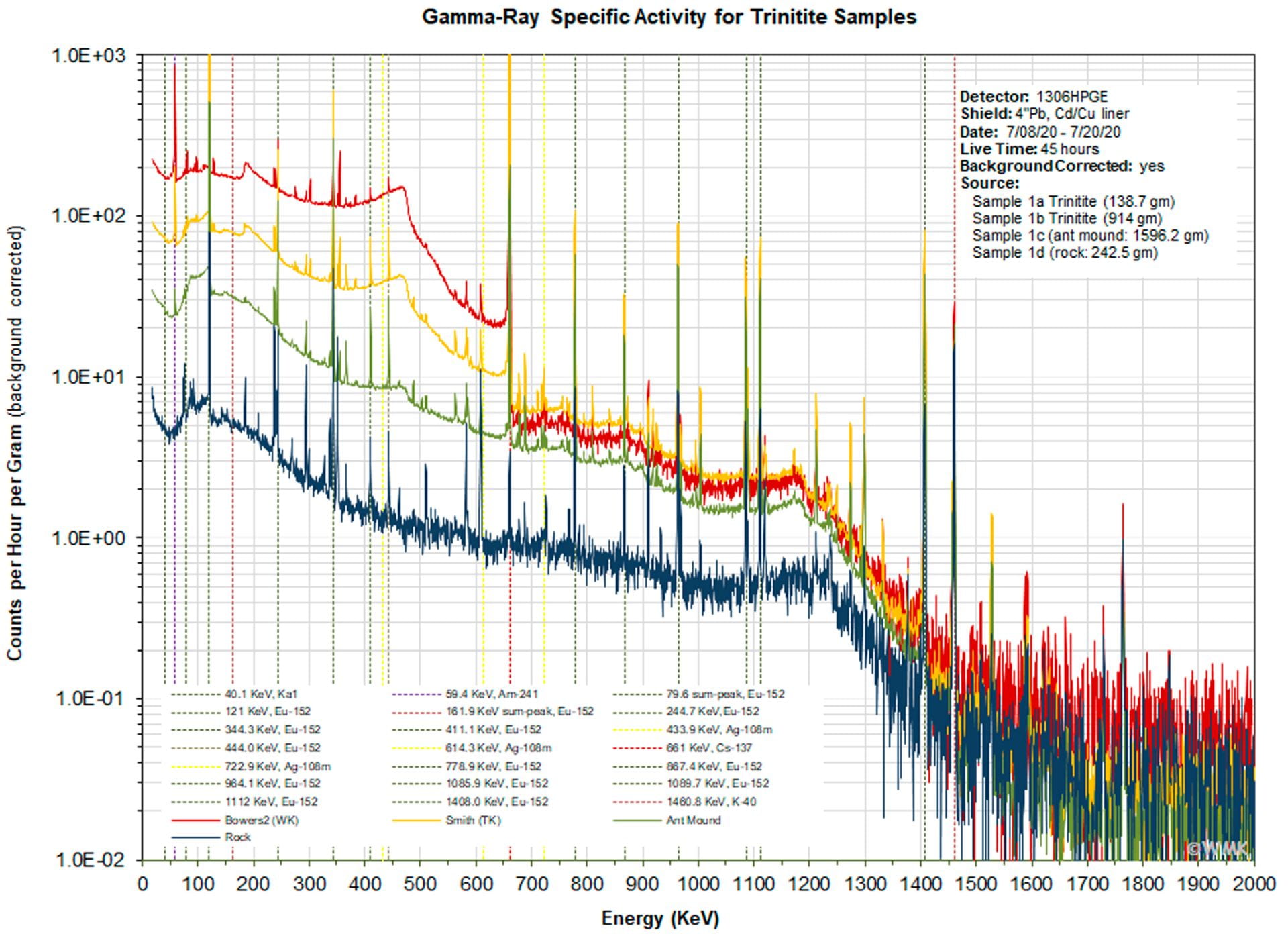
The explosion of the first atomic bomb left a crust of radioactive green glass on the New Mexico desert that extended about 1000 feet in all directions from Ground Zero. The green glass was called Trinitite and the fallout pattern during the first dozen seconds was permanently sealed in its surface. The rest is desert soil containing neutron activated isotopes that are related to distance from Ground Zero. Subsequent site surveys revealed an uneven pattern of radiation that increased toward Ground Zero and was greater where the Trinitite layer was thicker. Radionuclides that have persisted to the present day preserve this history and the gamma-ray spectra of many specimens appear to be unique to where it was collected and even who collected it. Using these spectra with supervised and unsupervised machine learning algorithms, we are classifying Trinitite samples and investigating their origins.

Samples of Trinitite, the radioactive residue left after the 1945 nuclear bomb test at the Trinity test site in New Mexico, have different radioisotope compositions with unique gamma-ray spectral signatures depending on when and where they were recovered. Our study looks at how machine learning algorithms can be applied for the classification of Trinitite by the sample’s gamma spectra as taken by high purity germanium (HPGE) detectors.

The Trinitite in question comes from a variety of sources, collection dates, and distances from Ground Zero. In order to determine the potency of machine learning classification, we experimented with unsupervised and supervised learning techniques, all of which were run on Python with the machine learning extension Sci-kit Learn. This study was inspired by NASA’s use of the Autoclass algorithm for determining classes of stars based on spectral components. The spectra from the HPGE detector was taken into the algorithm as is, giving each sample 4096 data components, or one for each channel. Given the high number of components for each sample, it was necessary to conduct a feature analysis to determine which components were actually influencing classification, thereby differentiating the Trinitite. The classifiers were run on abbreviated data for the spectral values at the components identified to be the most influential. The Trinitite study applies support vector, Gaussian-Naive Bayes, K-Means with principal component analysis, and HDBSCAN to determining the classes of Trinitite. The supervised classifiers (SVC and GNB) were trained with the full and abbreviated spectra of the data and tested with the rest. The unsupervised learning mechanisms did not need training data; however, the K-Means required a reduction in dimensionality to yield better groupings. HDBSCAN is unique in its ability find outliers in the data by analyzing if a sample’s spectra does not match the patterns of the other samples.